 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClosing the Loop: Motion Prediction Models beyond Open-Loop Benchmarks
May 08, 2025Fueled by motion prediction competitions and benchmarks, recent years have seen the emergence of increasingly large learning based prediction models, many with millions of parameters, focused on improving open-loop prediction accuracy by mere centimeters. However, these benchmarks fail to assess whether such improvements translate to better performance when integrated into an autonomous driving stack. In this work, we systematically evaluate the interplay between state-of-the-art motion predictors and motion planners. Our results show that higher open-loop accuracy does not always correlate with better closed-loop driving behavior and that other factors, such as temporal consistency of predictions and planner compatibility, also play a critical role. Furthermore, we investigate downsized variants of these models, and, surprisingly, find that in some cases models with up to 86% fewer parameters yield comparable or even superior closed-loop driving performance. Our code is available at https://github.com/continental/pred2plan.
Knowledge Augmented Machine Learning with Applications in Autonomous Driving: A Survey
May 10, 2022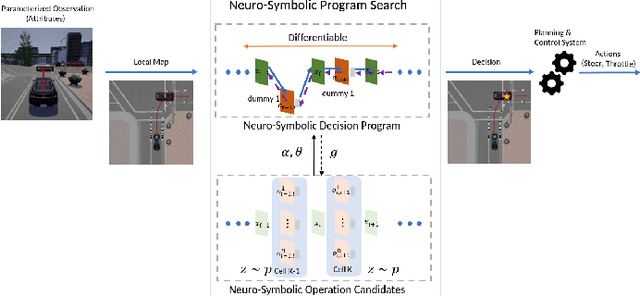
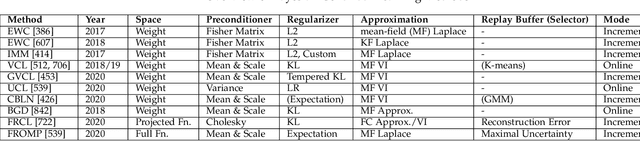
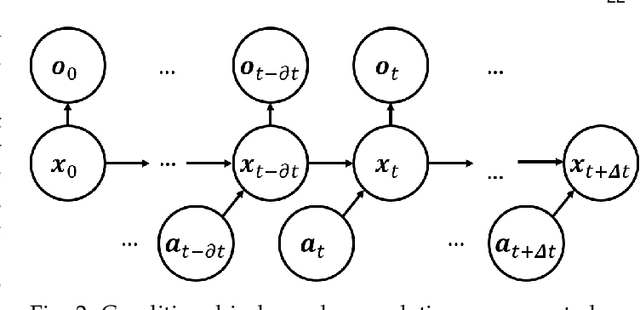
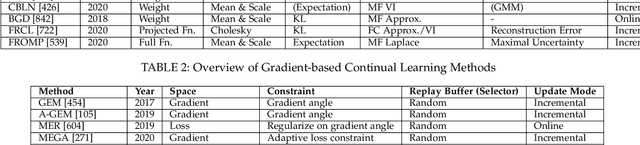
The existence of representative datasets is a prerequisite of many successful artificial intelligence and machine learning models. However, the subsequent application of these models often involves scenarios that are inadequately represented in the data used for training. The reasons for this are manifold and range from time and cost constraints to ethical considerations. As a consequence, the reliable use of these models, especially in safety-critical applications, is a huge challenge. Leveraging additional, already existing sources of knowledge is key to overcome the limitations of purely data-driven approaches, and eventually to increase the generalization capability of these models. Furthermore, predictions that conform with knowledge are crucial for making trustworthy and safe decisions even in underrepresented scenarios. This work provides an overview of existing techniques and methods in the literature that combine data-based models with existing knowledge. The identified approaches are structured according to the categories integration, extraction and conformity. Special attention is given to applications in the field of autonomous driving.
Comparative Study for Inference of Hidden Classes in Stochastic Block Models
Jul 13, 2012



Inference of hidden classes in stochastic block model is a classical problem with important applications. Most commonly used methods for this problem involve na\"{\i}ve mean field approaches or heuristic spectral methods. Recently, belief propagation was proposed for this problem. In this contribution we perform a comparative study between the three methods on synthetically created networks. We show that belief propagation shows much better performance when compared to na\"{\i}ve mean field and spectral approaches. This applies to accuracy, computational efficiency and the tendency to overfit the data.
* 8 pages, 5 figures AIGM12